과금 통한 수익 확대에 '데이터 권력화' 우려도
[서울=뉴스핌] 김지완 기자 = 포털 공룡으로 불리는 네이버가 데이터 산업에서도 최상위 포식자 지위를 노리고 있다. 검색데이터 기반의 데이터 생태계를 구축해 4차산업 전반의 지배력을 키우려는 포석이다.
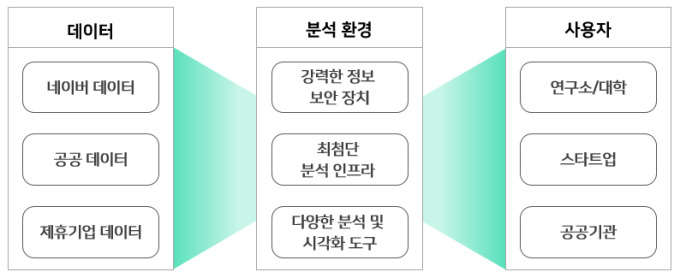
최근 네이버는 연내 '데이터 샌드박스'를 정식 오픈할 계획이라고 밝혔다. 데이터 샌드박스는 네이버가 보유한 자사 데이터와 공공데이터, 제휴를 통해 확보한 외부 기업 데이터를 한 데 모아, 보안성 높은 클라우드를 통해 활용하는 데이터 플랫폼이다. 이를 앞으로 연구소·대학, 스타트업, 공공기관이 이용하게 된다.
25일 과기정통부에 따르면 국내 데이터산업 시장규모가 2016년 13조7547억원, 2017년 14조3530억원, 2018년 15조5684억원 등 매년 평균 8.5%씩 성장세다.

◆ 플랫폼서 탄생한 AI 비즈니스, 네이버와 수익 공유+데이터 의존 심화
네이버 관계자는 데이터 샌드박스에 대해 "'자유롭게 데이터를 갖고 놀아보라'는 의미를 담고 있는 플랫폼"이라고 설명했다. 샌드박스 안에서 데이터 분석·가공 통해 AI 연구, 학술활동, 스타트업 비즈니스 개발, 공공기관 정책개발 등을 해주길 바라는 것이란 설명도 덧붙였다.
다만 표면적으로는 '데이터 놀이터'를 표방하고 있지만, 속내를 들여다보면 네이버 클라우드 수익 증대와 AI 스타트업 지배력 확대에 방점이 찍혀 있다. 네이버 관계자는 "네이버 데이터 샌드박스 데이터는 어떤 경우라도 외부 반출이 안된다"며 "네이버 클라우드에 해당 데이터가 저장돼 있고, 데이터 이용량 만큼, 인프라 비용(서버 비용)을 과금하는 구조"라고 답했다.
만약 스타트업이 샌드박스 데이터를 이용해 AI를 개발해 비즈니스에 나선다면, 스타트업 매출 증가에 네이버 클라우드 매출이 연동될 수 있는 구조다. AI가 해당 데이터를 DB로 활용할 경우, 네이버 클라우드에 저장된 데이터를 계속 끌어다 쓸 수밖에 없기 때문이다. 이는 결국 네이버 지배력 상승으로 연결될 수 있다.
이 같은 지적에 네이버 측은 "아마 그런 상황이 되면 데이터 사용에 대한 별도 계약이 체결될 것"이라며 "아직 CBT(베타 테스트)도 진행하지 않은 상황이어서 지금 뭐라 말하긴 조심스럽다"고 전해왔다. 이어 "대학·연구소·스타트업 등이 비용에 있어 부담을 갖을 수도 있겠지만 천문학적인 이용료가 청구되는 일은 없을 것"이라며 "연구진·스타트업 등이 충분히 비용을 부담할 수 있는 액수를 부과할 것"이라며 해당 플랫폼이 상업성 논란으로 번지는 것에 대한 의혹을 차단했다.
반면 IT업계의 생각은 다소 달랐다. 클라우드업계 고위관계자는 "클라우드는 수익구조가 단순하다"며 "데이터를 저장할 땐 돈이 안 들지만, 클라우드에 저장된 데이터를 꺼내쓰면, 쓰는 만큼 비용이 발생한다. 또 꺼내 쓸 데이터가 많으면 많을수록 기업은 해당 클라우드에 종속될 수밖에 없다"고 전했다.
다시 말해, 네이버 데이터 생태계에서 탄생한 AI 등 4차산업 기업은 네이버와 수익을 공유해야하고, 네이버에 보유한 데이터에 의존할 수밖에 없단 얘기다. 포털 사업으로 얻어진 검색 기반의 알짜 데이터가 국내 4차산업을 키우는 자양분이 됨과 동시에 지배력을 확대하는 수단이 된 셈이다.
◆ 네이버, 단순 관리자 넘어 강력한 통제권...'데이터 권력화' 학계 우려도
또 '데이터 놀이터'임에도 불구, 정작 기업이나 연구자들은 자유롭게 뛰어놀 수 없다는 것도 한계로 지적됐다. 네이버가 단순 관리자를 넘어 데이터 이용에 대한 강력한 통제권을 행사하기 때문이다.
네이버 측은 "샌드박스 데이터를 이용해 AI(인공지능)·SW(소프트웨어)·정책 등을 개발하는 사람들은 네이버와 개별 계약을 체결하게 된다"며 "이들에겐 각기 다른 데이터가 제공된다"고 밝혔다.
이어 "우리가 보유한 데이터 레벨에 따라, 1등급(Tier1), 2등급(Tier2)으로 데이터를 세분화할 계획"이라면서 "등급별 데이터 수준에 따라 보안규정도 달라진다"고 부연했다.
데이터에 개인정보가 포함됐다면 네이버 엄격한 통제가 따른다. 네이버 측은 "개인정보 관련 데이터는 별도 독립된 데이터 결합전문기관에 의뢰해 데이터 매칭을 의할 계획"이라면서 "이 경우 전체 데이터는 제공이 안된다. 매칭된 데이터만 연구자·스타트업 등에 제공할 것"이라고 밝혔다.
오래전부터 학계에선 '데이터 권력화'를 예견하고 우려해왔다.
최준균 카이스트 교수는 뉴스핌과 통화에서 "데이터가 없으면 인공지능은 무용지물"이라며 "데이터가 있어야 인공지능이 돌아간다. 데이터를 가진 자와 안 가진 자가 옛날 빈부격차가 발생하는 것처럼 데이터를 많이 가진 사람들은 점점 데이터를 갖고 권력을 휘두르는 상황이 생길 것"이라고 우려를 표했다.
최 교수는 "데이터를 모든 사람들이 활용할 수 있도록 공개적으로 열어야 하는데, 데이터를 가진 사람들이 그렇지를 못하다"며 민간기업 데이터 공개에 대한 회의감을 드러냈다.
swiss2pac@newspim.com