





펀치 카드의 추억
필자가 대학 1학년때 배운 컴퓨터 언어가 ‘포트란’이라는 과학기술용 컴퓨터 언어였다. 이러한 컴퓨터 언어란 인간과 컴퓨터의 소통을 가능하게 해주는 도구이다. 그 포트란은 주로 수학과 과학기술 계산에 편리한 컴퓨터 언어였다. 1980년대인 그때 학교에서 포트란 언어를 읽고 실행하는 컴퓨터가 IBM360/380 시리즈로 기억 한다. 그런데 프로그램을 직접 짜면 ‘펀치카드’라는 두꺼운 종이에 구멍이 뚫리는 방식으로 프로그램이 기록이 된다.
지금 생각해 보면 아주 원시적인 기록이며 컴퓨터 입력 방식이다. 타이프 치듯이 프로그램을 입력하면 이 펀치카드 종이에 구멍이 뚫린다. 이렇게 완성된 이 수 십장, 또는 수 백장의 펀치카드 뭉치를 학교 전산실에 제출하고 그 이후 1-2일 후에 계산 결과를 얻는다. 그때 계산 결과는 종이에 숫자 형식의 데이터로 프린트 되어 나온다. 그러니 1980년대초 컴퓨터의 입력은 종이에 구멍이 뚫린 펀치카드였고, 출력은 프린트 용지였다. 종이가 많이 필요했다. 이때 프린트 용지 맨 바깥쪽에는 프린트 기기에 쉽게 연결이 되게 작은 구멍이 아래 위로 쭉 뚫려 있었다. 이 수 백장의 프린트 용지는 추후 전공 관련 수학 수식을 풀때 요긴하게 쓰인 ‘이면지’였다. 종이가 이면지이자 컴퓨터와의 소통 방식이었다.
그런데 한번 포트란 프로그램에서 실수를 하면 몇 일이 지난 후에야 그 결과를 보고, 다시 고치고 입력해야 한다. 디버깅에 시간이 엄청 많이 걸린다. 그래서 프로그램을 짤 때 실수를 최소화해야 한다. 그때 필자는 학교를 전철을 타고 다녔는데, 전철에 앉아 펀치카드에 입력된 프로그램의 오류를 찾기 위해 몇 번이고 다시 검토하고 읽어 보기도 한 기억이 난다. 이처럼 이러한 초기 컴퓨터의 입출력 방식은 수시로 고치고 편집하거나 다시 실행하기 어려웠다. 그리고 종이의 낭비가 심했다고 볼 수 있다. 요즘 말로 ‘copy’, ‘paste’ 가 불가능하다. USB 에 작게 담거나 인터넷으로 파일을 보낼 수도 없다. 그때는 펀치카드 한 개의 박스로 담아 이동했다. 시간과 비용이 많이 드는 소통방식이다.
그 이후 몇 년이 지나 애플 8비트 컴퓨터가 학과에 한 대가 도입이 되었다. 이제는 펀치카드나 프린트 종이 필요 없이 화면을 보고, 프로그램을 편집하고, 입력하고, 그 계산 결과도 바로 화면으로 보았다. 컴퓨터와의 소통에 종이가 사라지기 시작했다. 편집이나 수정은 한 줄, 한 줄 했다. 요즘처럼 화면 전체를 왔다 갔다 하면서 고친 것이 아니라, 한 줄, 한 줄 고쳤다. 그야말로 줄 편집(line editing)이었다. 이 때 사용한 프로그램으로 ‘베이직’이 기억한다. 이후 IBM XT/AT 개인용 컴퓨터가 등장하면서 컴퓨터가 더욱 대중화 되었다. 워드 프로세서도 등장했다. 이제 펀치카드는 사라졌다. 이처럼 컴퓨터가 발전하면서 입력, 출력 장치도, 다르게 말하면 소통 방식도 인간에게 더 편리하게 발전해 왔다. 따라서 인공지능 컴퓨터의 입출력 형태와 소통 방식도, 또 다시 진화할 것으로 기대한다.
인공지능의 입력과 출력
현재 가장 많이 사용되고 있는 대표적인 인공지능 알고리즘이 CNN(Convolution Neural Network)이다. 주로 사진 이미지나 동영상을 판독하고, 이해하는데 사용하는 알고리즘이다. 특히 인터넷과 유튜브에 널린 수많은 사진과 영상 자료가 CNN 학습 데이터가 된다. 이때 컴퓨터가 자동적으로 인터넷에서 읽어서 긁어 모은다. 펀치카드도 필요가 없고 자판기도 필요가 없다. CNN은 이들 사진들을 입력하고, 출력으로는 예를 들어 그 사진 속의 물체를 인식(Classification)하거나 사진(Image) 속의 장면으로 글(Caption)로 쓰거나, 이야기(Text)를 만들 수도 있다. 또는 사진 속의 인물이 다음에 할 행동을 예측(Prediction)하거나 추후 일어날 사건을 예측한다. 또는 화면 속의 상황을 이해(Explain)할 수 있다. 이렇게 CNN의 출력은 ‘Tag(이름), ‘설명문(Caption)’, ‘문학 작품(Text)’이 되기도 한다. 때로는 음성 단어나 스토리로 만들어 출력할 수도 있다. 그리고 더 나아가 그 내용에 맞게 영상도 제작 가능하고, 음악도 창작 가능하고, 그림도 창작 가능하다. 출력으로 창작물을 만들 때 GAN(Generative Adversary Network) 알고리즘이 CNN과 같이 결합될 수 있다. 이 경우 출력은 창작 그림, 시, 문학작품, 음악, 영화도 된다.
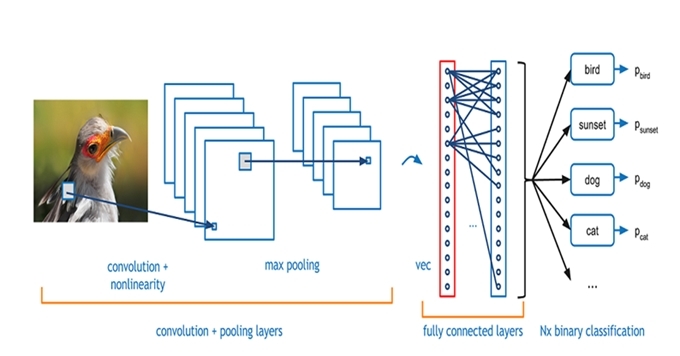
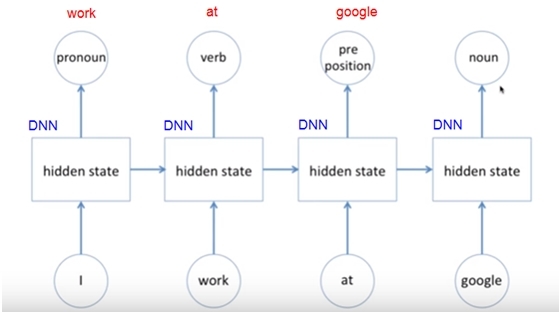
인공지능에서 CNN 다음으로 많이 사용하는 알고리즘이 RNN(Recurrent Neural Network)이다. 주로 시간 차이를 두고 순차적으로 입력되는 데이터의 해석과 이를 기초한 미래 예측에 사용된다. 대표적으로 사용하는 말을 알아듣는 인공지능 알고리즘이다. 말은 문법에 따라 순서대로 들어 온다. 그래서 입력의 순서에 따라 의미와 해석이 달라진다. 이 때문에 인공지능이 컴퓨터 내부에서 순차적으로 데이터를 받아 들이고, 순차적으로 학습하고 판단하도록 설계되어 있다. 다른 말로 시간과 순서 개념이 있는 인공지능이다. 그래서 RNN의 입력은 문장 혹은 사람의 말이 된다. 또는 영화의 장면과 장면의 연속이 입력이 될 수 있다.
책 한 권 전체가 RNN의 입력이 될 수도 있다. 그 속에 단어가 순서대로 나열되어 있게 때문이다. 더 나아가 인류가 유사이래 만든 모든 문서, 모든 책이 RNN 의 입력이 될 수 있다. 여기에 전세계 수 백 개 언어의 책과 문서, 녹음 파일 전체가 입력 데이터가 되는 엄청난 분량이 된다. 인공지능 컴퓨터가 책을 모두 쉽고 빠르게 읽는 입력 장치만 개발되면 된다.
전화 상담하면 녹음이 되고, 디지털화되면 그 파일이 바로 RNN의 입력이 된다. 지하철 속에서 주고 받는 대화 모두가 누군가 기록한다면 RNN 입력이 된다. 스마트폰으로 주고 받는 문자와 통화내용도 입력이 된다. 집에 설치된 아마존 인공지능 스피커도 ‘알렉사’도 RNN 입력이 된다. 그래서 CNN의 영상 이미지 이상으로 많은 RNN 입력 데이터가 지구상에 존재한다.
이러한 RNN의 출력은 ‘정답’, ‘독후감’, 설명문’ 또는 ‘다음 문장’이 된다. 입력 데이터를 읽고 이해하고, 그 전체를 요약하거나 문맥을 설명하는 것이 출력도 된다. 또는 그에 해당하는 사진이나 영상을 출력할 수도 있다. 또는 입력 문장에 맞게 음악, 그림, 소설, 영화 등을 창작할 수 있다. 이때는 RNN 과 GAN이 결합해야 한다. 이처럼 RNN의 입력은 문자이나, 녹음, 영상, 책이 되고 출력은 단어, 해설, 또는 창작물이 된다. 이것이 RNN의 소통방식이다.
궁극적인 인공지능의 입출력
결국 인공지능이 사람같이 생각하고, 행동하고 교류하려면 입출력 방식이 인간을 닮은 모습이 아닌가 한다. 결국 인공지능 소통 방식이 인간과 같아야 한다. 그렇게 되면, 인공지능의 입력은 사람처럼 말을 알아 듣고, 눈으로 볼 수 있어야 한다. 그리고 인공지능의 출력은 말을 하거나 글을 쓰거나, 단어로 표현하거나 한 단계 더 나아가, 문장, 소설, 시, 그림, 음악, 영화와 같은 창작물이 될 수 있다. 더 똑똑한 인공지능은 말을 하지 않아도, 문맥이나 표정만 보고 알아서 판단하고 행동을 하면 더 좋다. 궁극적으로 말 끼를 알아듣고, 눈치가 빠른 인공지능이 되어야 한다. 그 때 인공지능은 IQ 뿐만 아니라 EQ 도 좋아 사회성과 도덕성을 가지면 더욱 바람직하다.
미래 자율주행자동차에서는 이런 인공지능의 입출력 방법이 인간과 인공지능 컴퓨터와의 소통과 대화의 방식이 된다. 자율주행자동차의 기능에서 인공지능 자체의 기능도 중요하지만, 인간과의 소통을 위한 입출력 기능도 그에 못지 않게 같이 중요하다. 그래야 완전한 자율주행자동차 시대가 된다. 결국 인공지능이 발전하면서 인공지능의 소통 기술도 함께 발전되어야 한다. 궁극적으로는 소통의 방식은 ‘인간의 모습’을 닮아 간다. 언제인가 인공지능의 소통 방식으로 ‘텔리파시’까지 사용될 수도 있다.
[김정호 카이스트 전기 및 전자공학과 교수] joungho@kaist.ac.kr

















