경량 모델 'Kanana Nano 2.1B' 오픈소스로 배포
[서울=뉴스핌] 양태훈 기자 = 카카오가 자체 개발한 AI 언어모델 'Kanana'의 연구 성과를 담은 테크니컬 리포트를 공개하고 국내 AI 생태계 활성화를 위해 경량 모델을 오픈소스로 배포했다.
27일 카카오는 자체 개발 언어모델 'Kanana'의 연구 성과를 담은 테크니컬 리포트를 아카이브(ArXiv)에 공개했다고 밝혔다. 또한 언어모델 라인업 중 'Kanana Nano 2.1B' 모델을 깃허브(GitHub)에 오픈소스로 배포했다.
테크니컬 리포트에는 카나나 언어모델 전체의 매개변수와 학습 방법, 학습 데이터 등 세부 사항과 함께 Pre-training부터 Post-training까지 전 과정이 자세히 담겼다. 카나나 모델의 구조, 학습 전략 및 글로벌 벤치마크 성과도 확인할 수 있다.
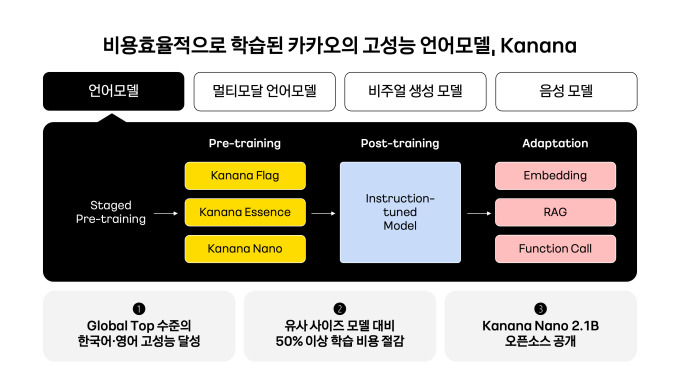
카카오의 초거대 언어모델 'Kanana Flag'는 지난해 말 학습을 완료했다. 이로써 카카오는 작년 10월 개발자 컨퍼런스 'if(kakaoAI)2024'에서 공개한 'Kanana Flag', 'Essence', 'Nano' 등 '카나나 언어모델' 전체 라인업을 모두 구축하게 됐다.
'Kanana Flag'는 한국어 성능을 평가하는 'LogicKor', 'KMMLU' 벤치마크에서 타 모델을 압도하는 처리 능력을 입증했으며, 영어 성능을 평가하는 'MT-bench', 'MMLU' 벤치마크에서는 경쟁 모델과 유사한 성과를 기록했다. 또한 학습 자원 최적화를 통해 유사 사이즈의 모델 대비 50% 이상 비용을 절감하며 최고 수준(SOTA)의 효율성과 성능을 동시에 구현했다.
카카오는 대규모 언어모델의 학습 효율을 극대화하기 위해 ▲Staged pre-training ▲Pruning(모델 구성 요소를 가지치기해 중요 요소만 남기는 기법) ▲Distillation(큰 모델의 지식을 더 작은 모델로 전달하는 증류 기법) ▲DUS(Depth Upscaling, 깊이 업스케일링) 등 혁신적 학습 기법을 적용했다. 이를 통해 경량 모델부터 초거대 모델까지 다양한 사이즈의 고성능 모델을 효율적으로 개발, 글로벌 유사 크기 모델 대비 절반 이하의 학습 비용을 실현했다.
오픈소스로 공개된 'Kanana Nano 2.1B'는 연구자와 개발자가 활용하기 적절한 크기의 모델이며, 온디바이스(On-device) 환경에서도 활용 가능한 고성능 경량 모델이다. 비교적 작은 규모임에도 유사한 크기의 글로벌 모델에 견줄 만한 성능을 보여주며, 한국어와 영어 처리 능력에서 뛰어난 결과를 나타낸다. 베이스 모델과 인스트럭트(Instruct) 모델, 임베딩(Embedding) 모델이 깃허브를 통해 제공된다.
카카오는 향후 카나나 모델에 강화 학습(Reinforcement Learning)과 연속 학습(Continual Learning) 기반의 최신 기술을 접목해 추론, 수학, 코딩 능력을 강화하고, 정렬(Alignment) 기술을 고도화해 사용자 요청의 수행 정확도를 높일 계획이다.
김병학 카카오 카나나 성과리더는 "모델 최적화와 경량화 기술을 바탕으로 라마, 젬마 등 글로벌 AI 모델과 견줄 수 있는 고성능의 자체 언어모델 라인업을 효율적으로 확보하게 됐으며, 이번 오픈소스 공개를 통해 국내 AI 생태계 활성화에 기여할 수 있을 것으로 기대한다"고 말했다.
dconnect@newspim.com