




우리는 어떻게 배우는가
필자가 처음 영어 공부를 시작한 것은 중학교 들어가기 전, 초등학교 6학년 때로 기억한다. 아마 공책에 a, b, c, d 알파벳을 필기체와 출판 서체로 연습한 기억이 난다. 그리고 영어로 배운 첫 문장이 “I am a boy,아니면 “You are a girl” 이 아닌가 생각한다.

본격적으로 영어를 공부한 시기는 고등학교 때이다. 그때 사용했던 영어 교재가 ‘성문종합영어’, ‘영어의 왕도’ , 그리고 ‘1200제’였다. 특히 그 중에 가장 어려운 교재가 ‘1200제”이었는데 아마도 일본 참고서를 번역한 책으로 기억한다.
그런데 이렇게 영어 공부를 시작할 때 재일 재미없었던 부분이 문법을 외우는 과정이었다. 명사, 대명사, 동사, 가정법 등 외우는 내용도 많고, 예외도 많았다. 그 규칙을 파악하고 외우고 이를 토대로 문장을 이해하고, 해석하고 작문하였다.
인공지능에서도 전통적으로 이와 비슷한 학습 방법을 써 왔다. 전통적 인공지능에서는 먼저 뇌와 지능의 동작 원리를 이해하고, 그에 맞추어 모델을 세우고 이를 컴퓨터 프로그램으로 구현하는 방법이다. 이 방법은 인간의 뇌의 동작을 인간의 논리로 파악하려 하는 방법이다. 영어 배울 때 문법으로 언어를 배우려는 시도와 같은 방법이다.

하지만 최근 딥뉴럴네트워크(DNN)으로 표현하는 인공지능은 빅데이터를 제공하고 그 데이터를 통해서 인공지능이 스스로 학습하는 방법이다. 이러한 방법을 ‘머신러닝' 인공지능이라고 한다. 여기서는 데이터를 믿고 학습한다. 이러한 머신러닝 학습 방법 중에서 인공지능 스스로 데이터를 만들어 내고 최적의 답을 만들어 내는 방법이 등장했는데, 이를 ‘강화학습(RL: Reinforcement Learning)’이라고 한다. 이를테면 컴퓨터 스스로가 자율학습을 해서 지능을 쌓아가는 방법이다.
아기가 처음 말을 배울 때 하는 말을 ‘옹알이’라고 한다. 옹알이를 통해서 엄마와 소통하면서 말을 배워나간다. 그때 처음 배우는 말이 ‘엄마’, ‘맘마’, ‘아빠’ 와 같은 단어들이다. 맘마라고 부르면 엄마가 우유를 주고, 엄마라고 부르면 엄마가 따뜻한 눈길을 주고 사랑으로 안아준다. 이처럼 아기가 언어를 배우는 과정에서는 아기가 주변 환경과 교류하면서 보상을 얻는 과정에서 말을 배운다. 우리처럼 문법을 통해서 배우지 않는다.
또한 아기가 걸음마를 배우는 과정도 비슷하다. 걷고, 넘어지고 다치면서, 시행착오를 거치면서 아장 아장 걷기를 배운다. 이때 환경은 거실 마루이고, 보상은 걷는 기쁨과 엄마의 웃음이다. 이처럼 주변환경 속에서 행동하고 보상 받으면서, 그 결과 최선의 결정과 행동을 하면서 학습하는 방법을 ‘강화학습’ 인공지능이라고 한다. 그래서 강화학습은 인간이 본능적으로 배우는 학습 방법이다.

시행착오 통한 강화학습, 로봇과 게임에도 적용 가능
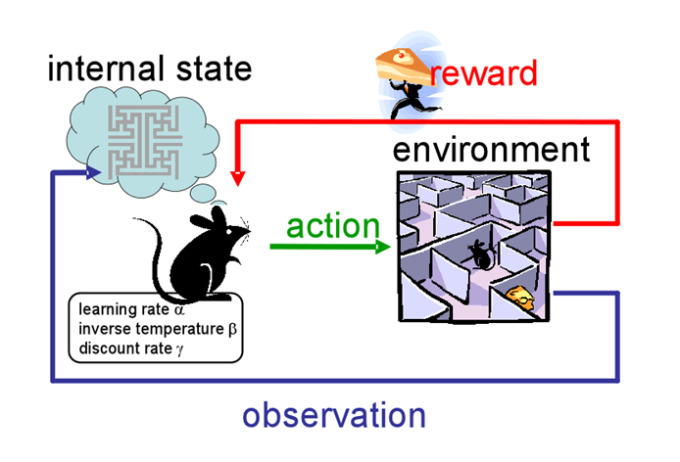
강화학습에서는 주변 환경(Environment)이 있고 그 상태(State)를 벡터로 표현한다. 다양한 시도(Action)와 보상(Reward)를 얻으면서 스토리(Episode)를 만들고, 그 결과로 환경을 파악해 간다. 이렇게 시행착오를 거쳐서 학습하게 된다. 그리고 최적의 정책(Policy)을 찾아간다.
생쥐의 미로 찾기 게임이 강화학습의 좋은 한 예가 된다. 이 때 미로의 구조가 환경이 되고, 최종적으로 치즈를 먹게 되면 보상을 얻게 된다. 그렇지만 최단 시간 내에 찾아야 하는 조건이 붙게 된다. 이처럼 각 상태에 따라 미래를 정할 수 있고, 과거는 묻지 않는 조건을 강화학습에서는 마르코프(Markov) 조건이라고 한다. 강화학습을 적용하려면 마크코프 조건을 만족해야 한다. 과거는 묻지 않고, 현재 상태로만 그의 미래를 점치는 조건이다. 과거까지 따지면 너무 복잡해서 보상을 예측하기 어렵기 때문이다.
강화학습은 로봇의 걷기 제어에도 적용될 수 있다. 로봇이 넘어지고 걷기를 반복하면서 인간에게 가까운 최적의 보행 제어를 이러한 강화 학습 방법으로 찾을 수 있다. 마찬가지로 이러한 학습은 드론의 조종, 헬리콥터 조종, 항공기의 조종 제어에 사용할 수 있다. 더 나아가 자율주행 자동차의 자동 운전에 강화학습이 사용되어 주어진 조건(State) 에서 최적의 자율 운전을 할 수 있다. 이때 최종적으로 주어지는 보상이 연료비의 절약이나 사고율 저하, 안전성 향상 등이 될 수 있다.
이때 시행착오의 과정은 시간과 비용이 든다. 자동차를 부수기에는 비용이 비싸다. 경우에 따라 시행과 보상을 컴퓨터 시뮬레이션으로 대신 하기도 한다.
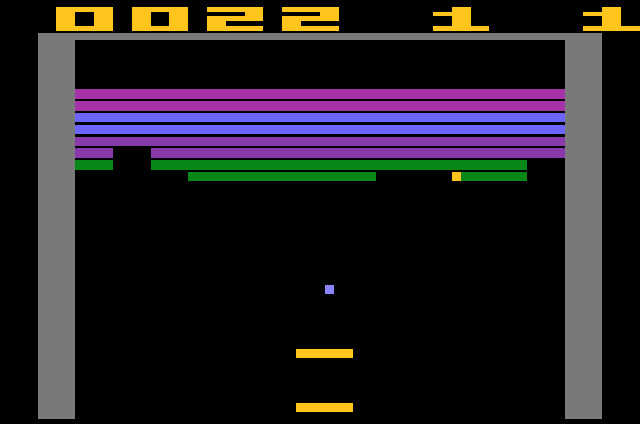
강화학습은 게임에 적용되기도 한다. 블록깨기(Atari Breakout)게임을 강화학습으로 하는 경우 금방 최적의 조건을 찾는 것을 볼 수 있었다. 돌이 블록 뒤로 들어가면 여러 번의 반사과정을 반복하면서 저절로 대부분의 블록이 격파되고 점수가 올라간다.
그래서 강화학습을 수행한 컴퓨터와의 인간과의 게임이 이제 더 이상 상대가 되지 않는다. 인공지능은 이런 경우뿐만 아니라 주식투자, 재고관리, 웹사이트의 광고 배치, 상품추천 등 다양한 분야에서 중요한 결정을 인간을 대신해서 할 수 있다. 인간처럼 이 때 보상은 경영상 이익이 된다. 컴퓨터는 졸거나, 피곤해 하거나, 술을 마시지도 불평하지도 않는다. 강화 학습으로 훈련한 보상 체계만 따를 뿐이다.
강화학습은 인공지능의 '무기'
이와 같이 강화학습은 데이터와 정답 없이 스스로 학습이 가능한 인공지능 알고리즘이다. 공부로 치면 자율학습 공부 방법이다. 인공지능이 데이터를 이용해서 학습하기 위해서는 데이터를 모으는 작업에서 많은 비용을 지불 해야 한다. 데이터 수거 장치, 전송 장치, 저장 장치에 투자해야 한다. 5G 무선 통신도 투자 비용이 크다. 그러면서도 데이터를 모으려면 개인의 허락을 받아야 하고, 개인 정보 보호 문제도 극복해야 한다. 그렇지만 강화학습은 데이터 없이 학습한다. 인공지능이 점점 강력해지는 또 다른 이유이기도 하다.
joungho@kaist.ac.kr
[김정호 카이스트 전기 및 전자공학과 교수]

















